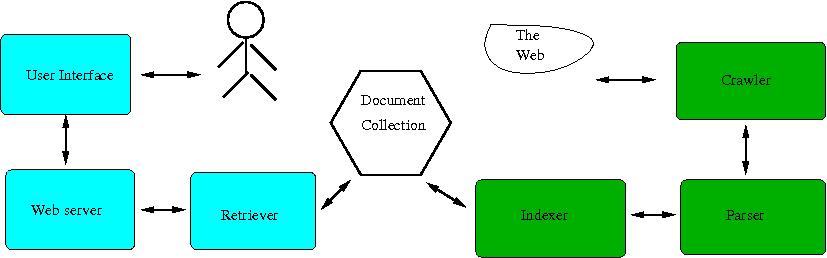
Figure: Architecture of A Simple Search Engine
In this project students in teams will create a simple, but functional search engine. The search engine collects and organizes information about online courses materials in the computer science department and provides the users a search interface like most of the search engines, e.g., www.google.com. The users should be able to enter a key phrase such as assembly or architecture and your search engine should be able to return a list of resources that contain the key word.
The software will consist a few components. The first one is a crawler that visits and collects information from course websites that are accessible, for example, http://www.eg.bucknell.edu/~cs363/ and http://www.eg.bucknell.edu/~csci203. Your crawler will read these web pages and break them into a list of words and URLs that come with the pages. The second component of the search engine is a web server, you will build a web server that will act as the basis of a search engine. When a user issues a query, the search engine will be able to respond with the data the server has. The third component is an inverted index, which is built from the web pages retrieved. Each word in this index points to a list of web pages that contain this word. When a query is given, the search engine looks through its inverted index list and returns the list of web pages that contain the key word. You can use some very simple mechanism to sort the returned list. Optionally, you can use a slightly more sophisticated ranking algorithm to rank the returned list. See Extra Credit for details.
This is a multi-phased team project. You can work in a team of two to three, or you can work alone. You are encouraged to work in teams. I would prefer you write the program in C, though other languages such as Python, Java, or a mix of them are acceptable.
Project assigned: Wednesday January 27th, 2016.
Phase 1: Monday February 8th, 2016.
Phase 2: Friday March 4th, 2016.
Phase 3: Monday March 28th, 2016.
Before implementing the project, I would ask all to keep the following in mind.
Note that it is fine to study these public code and algorithms used in these code, and implement the ideas by yourself (that is, you can't just copy-and-paste the code in its entirety or use a set of libraries without doing the three things listed above.) In this case, you should also quote the references.
nice command to lower the priority of your process.linuxremote or linuxremote1, linuxremote2, and linuxremote3.) Rather, run your program in lab computers in Dana 132, Dana 213, Breakiron 164, or Breakiron 167. You may remote log into the servers, but please ssh into the lab computers before running your programs. The names for these lab computers are dana132-lnx-n, dana213-lnx-n or brki164-lnx-n where n is a number, e.g., 1-24, depending which lab.fork(). The one thread (process) that visits web servers must pause or sleep after visiting every a few tens of pages.A search engine consists of two major parts, somewhat independent of each other, as can be seen from the figure. One part is on the left side of the Document Collection, which answers user queries. A user interacts with the search engine typically through a browser. The user query is sent to the retriever through the web server to retrieve the collection of URLs relevant to the query. The other part is on the right side of the Document Collection, which collects information from the web so the URLs related to the user queries can be retrieved. A crawler goes around the web to read web pages. The information is then sent to a parser that breaks down the web pages into a collection of words and extracts URLs within the web page. These URLs are pointing to other web pages on the internet from this web page. If the current given web page is denoted as w and the URLs extracted from w are s, then effectively page w is pointing to each page si for all i in the set s. When a user issues a query the document collection is searched and a list of URLs containing the search key word is generated. Each of the URLs presented as an answer to the query is pointing to the queried web page (target). The data structure that keeps this information and enables the user search is what indexer builds and augments. Because in this data structure a word in a document is pointing to URLs contained in this document, we call it a reversed indexing system.
Figure: Architecture of A Simple Search Engine
The first phase of the project is to retrieve a web page and parse out all the URLs contained in the web page. You are to construct a TCP client program that is able to send an HTTP GET request to a web server and retrieve the page back from the server. Once a page is retrieved, the second task of this phase is to parse out all the URLs in the page.
An HTTP client (a.k.a. web client) establishes a connection to a web server through a TCP socket. After creating the socket, the client makes a connection request to the server, the server acknowledges the connection and the communication between the server and the client is established. Once a TCP connection is ready, the client can send either an HTTP 1.0 or an HTTP 1.1 request. The server will send back the page being requested. The client then can process the web page as needed.
See the web client program example for code details. The client program in that example uses a library tcplib.c. You are asked to use your own wrapper programs developed before, e.g., in CSCI 315. In addition, the example program simply prints the received web page to the standard output (screen), your program must save the content in a string variable that can be used by other parts of the program.
The second task in this phase of the project is to parse out all URLs contained in the received page. The following is a simple web page that contains multiple URLs. Your task is to extract all the URLs and to complete the URLs that are relative.
In the code example directory, some utility programs are provided that may help you extract a URL and convert it to its absolute form. In particular, look at the program library htmllinks.c and its associated files including the Makefile.
Here are discussions on some technical details that may help you to carry out the task.
http://www.eg.bucknell.edu/~xmeng/teaching.html#eg290. When an absolute URL is extracted from a web page, it can be used directly to retrieve the web page specified by the URL. On the other hand, a relative URL gives a path relative to the current web page. For example if the web page from which the relative URL is extracted is http://www.eg.bucknell.edu/~xmeng/index.html (often called a base URL) and a relative URL from the given page is extracted as ../teaching.html, then the absolute URL should be http://www.eg.bucknell.edu/~xmeng/teaching.html. Your program will need to convert all relative URLs to absolute URLs.The basic strategy to convert a relative URL to an absolute URL is to scan the URL file path from left to right, every time a current directory notion "./" is met, you simply remove these two characters from the URL; every time a parent directory notion "../" is met, you remove the directory name above this level. For example, a relative URL "level1/./level2/../level3/file.html" is given, its absolute form should be "level1/level3/file.html" after the process.
When the file path scan and conversion is finished, attach the entire path to the current host (e.g., http://www.bucknell.edu/ or http://www.cnn.com/.)
You can approach the problem in many different ways. Here is what I would suggest.
socket interface first, similar (or identical) to the example given in code/web-client-server-c/webclient.c. This client program should be able to retrieve a web page from a given URL.The examples in this directory may help you work on the project.
The two files fsm-url.c and regexp-url.c are two different ways of extracting URLs out of a web page. fsm-words.c is a simple example of parsing a piece of text into a collection of words. testpaths.c uses path_util.c to convert each of the relative URLs in a page into an absolute URL.
You are to submit to your Gitlab account the following by the deadline for this phase.
project1 folder under your csci363 you created earlier, upload (push) all your files in the project1 directory by the deadline.