


Next: About this document
INTERNET SEARCH
- An Integral P
art Of Internet B
ased Computing
Xiannong Meng
Department of Computer Science
The University of Texas - Pan American
meng@panam.edu
October 20, 1998
Outline of the Presentation
- Internet activities: information service and parallel
computing.
- Information service: search, cache, retrieval, visualization,
ranking and others.
- Parallel computing: objectives, models, promises and
problems.
- Internet Search Technologies
- Our Work (DaVIME and search)
- Conclusion
Information Service Over the Internet
- Estimated a lower bound of 320 million pages on the Internet

- Search service strategies:
- Issue of caching and proxy server
- Internet Cache Protocol : if-modified-since
- Squid is one implementation of ICP.
- Proxy servers: used in ICP.
Information Service ... continued
- Visualization (RHF's talk)
- Ranking and relevance(!) (RHF and others' work)
- View the Web as a database : designed for resource and knowledge discovery in a global
information system; uses multi-layered database architecture.
Parallel Computing Over the Internet
- Javelin: Clients request computing
power from hosts with the help of brokers; Java-based.
- ParaWeb: Clients use internet and intranet as a
part of their computing infrastructure in a seamless fashion. The use
of a scheduling server (broker).
- ATLAS: Manager,
clients, and computing server, software system, work stealing.
- Legion: Virtual supercomputing based on campus
wide network.
- Globus: Supercomputers connected by
Internet where major scientific computation tasks can be carried out.
- Related project GUSTO won the GII (Global
Information Infrastructure Next Generation) award on April 20, 1998
- Related project I-Way : is an ATM
network connecting supercomputers, mass storage systems, and advanced
visualization devices at 17 different sites within North America.
Internet Search
- Some major search engines attempt to maintain full-text
indexes of WWW. Each has limited scope.
- Meta-search: get results from those major search engines,
digest and organize the contents before presenting to users -
MetaCrawler, SavvySearch
and others. Reply on the documents and summaries provided
by the search engines.
- One step further, use meta-search technique and analyze the
contents before presenting it to the user.
The NECI Metasearch Engine
- See Figure 1 in the paper for illustration
- Key: download and analyze results before displaying to
user.
- Result ranking:
- number of queries in the document
- proximity between query terms (distance measured in
number of characters)
- term frequency
- Parallel retrieval of the pages
DaVIME
DaVIME - Data Visualization, Indexing and Mining
Engine, which is a parallel computing architecture for information
service over the Internet.
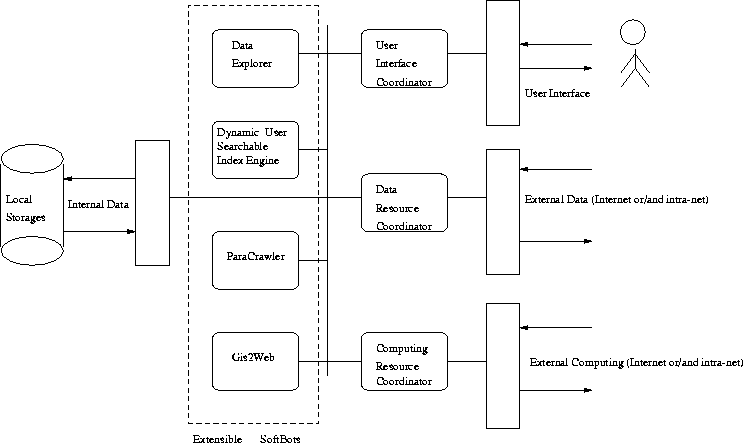
Figure: System Architecture of DaVIME
ParaCrawler
- Create our own meta-search engine so we can experiment with
various policies and mechanisms
- ParaCrawler: parallel search, ranking, sorting, pruning ...
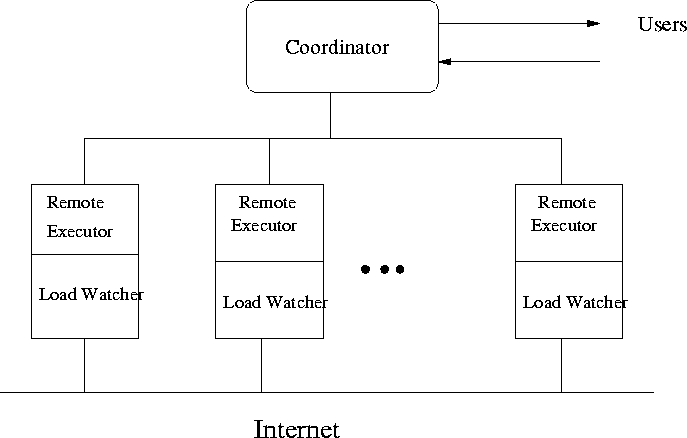
Figure: ParaCrawler Structures
Web Search Using Personalized Information
- So far most work concentrated on general search results
- On a closer look, most users use a set of fixed computers to
do Web search
- That leaves a lot of 'digital traces'
- Use these information can help improve search result
- Examples: word frequency, cached URLs, ...
- Parallel retrieval to improve latency
Conclusion
- Internet can be used as a global scale, desk-top supercomputer
using existing technologies
- Internet can support computing as well as information
engineering
- Build a system that can make use of idle computing powers
- Use the idea of meta-computer and meta-search engines
Next: About this document
Tue Oct 20 16:27:20 CDT 1998