 |
CSCI379.01 Term Project
Fall 2003
First Phase Assigned: Monday, September 1, 2003
First Phase Due: Wednesday
September 17th, 2003
The goal of the project is to produce a limited scale, but functional search engine. The search engine should be able to provide a list of relevant documents when a query is given, just like any commercial search engine would do. It is in a limited scale that it is required to collect a limited number of documents (e.g. in the order of a few hundreds to a few thousands). The more your search engine can collect, the better it is.
This is a multi-phase, team project. It will start from the beginning of the semester and last through the semester. The detailed scope of the project, the team organization, technical information, and other details will be given as the semester progresses. An overview and the first part of the project will be given here.
A search engine consists of a collection of software components that work together to accomplish the task of collecting, analyzing a large number of documents over the Internet and giving the user a list of relevant documents and URLs when a query is issued to the search engine.
Major components of a typical search engine include the following:
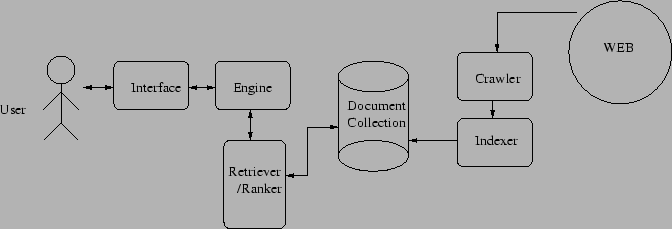
Figure 1 indicates the relation among different components in a typical search engine.
A search engine consists of two major parts, somewhat independent of each other, as can be seen from the figure. One is on the left side of the document collection, which answers user's queries. The other is on the right side of the document collection, which collects information from the Web so the URLs related to the user queries can be retrieved. A crawler goes around the Web to read Web pages and to extract information about each Web page it reads. The information is then sent to an indexer. The indexer takes this information and creates the links between keywords and the documents that contain these keywords. The result is typically saved into a file or a collection of files. When a user issues a query the document list is searched and a collection of relevant documents is generated. The ranker is responsible to rank these documents according to certain algorithms and measures. The top ranked documents are returned to the user for review. It is possible for the user at this point to review the documents and send feedbacks to the search engine. The ranker may take these feedback into account and re-select or re-rank the documents for user to view.
The project will be carried out in teams. The details of the team work are given in a separate handout.
Your phase one work is to implement a basic version of the interface and the back-end engine. This is just a framework. As the project progresses, some of these components will need to be enhanced. The interface part is responsible for the following main tasks.
There are some code examples in the directory of
![]() http://www.eg.bucknell.edu/~xmeng/Course/CS379/code/javaServer/
http://www.eg.bucknell.edu/~xmeng/Course/CS379/code/javaServer/![]() for
this part of the
project. Students who use C++ may find a similar example in C in the
directory of
for
this part of the
project. Students who use C++ may find a similar example in C in the
directory of
![]() http://www.eg.bucknell.edu/~xmeng/Course/CS379/code/cServer/
http://www.eg.bucknell.edu/~xmeng/Course/CS379/code/cServer/![]() . You
should try out these examples, observe their behavior
before you design and develop your own program. Do the following.
. You
should try out these examples, observe their behavior
before you design and develop your own program. Do the following.
javac EasyWebServer.java
java EasyWebServer port#where the
port# is an integer of your choice. There are two
restrictions for this number. It has to be greater than 1024. Port
numbers below 1024 are reserved for system applications (for example,
email server at port 25, telnet server at 23 and ftp server at
21). The second restriction is that the port number has to be
unique. There cannot be two applications running at the same port on
the same machine.
polaris.eg.bucknell.edu and the port is the port
number you chose to run the server in the previous step. For example, if
the Web server is running on polaris at port 9999, then
you should point your Web browser at
http://polaris.eg.bucknell.edu:9999/
http://polaris.eg.bucknell.edu:9999/sample.html http://polaris.eg.bucknell.edu:9999/searchThen read the programs and make sure you understand what the program is doing.
Let's discuss some technical details as we walk through an example. Assume the search engine is running at host polaris at port 9999. we have issued the URL in our browser as
http://polaris.eg.bucknell.edu:9999/searchAn HTML form will be displayed in the browser as the result. We typed ``123'' in the first input box and ``abc'' in the second input box and then we clicked on the button ``Submit''. Let's now exam what happens between the browser and the server.
get /path http/1.1 \r\n\r\nThis means the browser is requesting (get) a page specified by /path and the protocol that the browser is using is HTTP 1.1. It is required to have two consecutive new lines to end the command, each of which consists of a new-line character and a carriage-return character.
In our example, the command sent to the server from the browser is
get /search http/1.1 \r\n\r\nThis resulted in the form to be displayed to the browser's screen.
In our example, when we fill in the form and click the ``Submit'' button, the browser is sending a ``post'' request to the search engine. The content of the form is sent to the server as the actual content after the header information.
GET / HTTP/1.0 Connection: Keep-Alive User-Agent: Mozilla/4.78 [en] (X11; U; SunOS 5.8 sun4u) Host: polaris:9999 Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, image/png, */* Accept-Encoding: gzip Accept-Language: en Accept-Charset: iso-8859-1,*,utf-8
POST /form HTTP/1.0 Referrer: http://polaris:9999/search Connection: Keep-Alive User-Agent: Mozilla/4.78 [en] (X11; U; SunOS 5.8 sun4u) Host: polaris:9999 Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, image/png, */* Accept-Encoding: gzip Accept-Language: en Accept-Charset: iso-8859-1,*,utf-8 Content-type: application/x-www-form-urlencoded Content-length: 44
Note that the last line indicates that the content length is 44 characters. In this case, after the header part (in the above display) the browser is sending a form containing data to the server in the following format.
FirstInput=123&SecondInput=abc&Submit=Submitwhich is exactly 44 characters. This string represents the form that is sent from the browser. The content length (44) and the content string depends on your input to the form. In our example, we typed ``123'' in the first input box and ``abc'' in the second input box. The content string is formed by the browser in the format of a sequence of name/value pairs. The name and value in a pair is separated by an equal sign ``='' and the pairs are separated by an ampersand sign ``SPMamp;''. In our example, FirstINput, SecondInput, Submit are the names of the form entries (read form.html to see where they are specified) and 123, abc, Submit are the values corresponding to these names.
Your team needs to hand in the following in the order given. Please staple all pages.
This document was generated using the LaTeX2HTML translator Version 2002-2-1 (1.70)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -nonavigation -split 1 project-part1
The translation was initiated by Meng Xiannong on 2003-08-31