Figure: A Set of Connected Web Pages
After completing the first two phases, now you have a pair of programs, a client program and a server program. The client program is able to retrieve a web page from a given website and to parse out all the words and URLs in that page. The server program is able to take a query from a web browser and can send back the first a few URLs that contain the search query.
Your next task is to further develop the client program so it can retrieve multiple web pages from multiple websites. We can call this program that is able to collect multiple web pages a crawler (Please refer to the architecture figure.) In addition to collecting and parsing the pages, you are to add the capability to your server so that the server will be able to return a list of web pages that contain a particular search query. Let's look at some of the details.
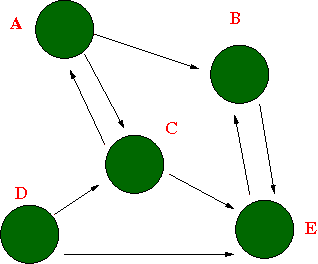
In Phase 1 of the project, you completed a client program that can retrieve a web page from a given URL and parse out all the words and URLs contained in that web page. Now if your client program follows each of these URL links harvested in the page to retrieve more pages pointed by these newly extracted links, the program becomes a crawler that is able to retrieve all web pages in a connected component of a web. The connected component here has exact the same meaning as you learned in your data structures course, that is, a root node (web page) can reach any node (web page) in the collection as a directed graph. Viewing from the graph perspective, a crawling process really becomes a traversing process. The starting web page becomes the root of a spanning tree in this directed graph, the task of a crawler is to traverse all the nodes in the graph by either a breadth-first traversal, or a depth-first traversal. For our purpose, we are going to pursue a breadth-first traversal. Depth-first traversal works in a similar way, using a different type of data structure. The following graph can represent a subset of web pages that connect to each other. If we start from page D, we'd be able to reach all pages by a breadth-first traversal in the order of D, C, E, A, B.
Figure: A Set of Connected Web Pages
How do we perform a breadth-first traversal in a graph from a given starting node x? We can use a queue data structure to solve this problem. Assume we have a starting web page x and a queue toVisitQ, a breadth-first traversal can be accomplished as follows.
We need to set a reasonable limit so the crawling process doesn't take too long. I would suggest a few hundreds to a few thousands as a limit. We can also gradually update this limit (see notes later in Section 3.3.)
A number of factors should be considered when deciding if a page should be visited. First of all, a page that has been visited before should be never visited again. Otherwise the traversal would go into an infinite loop. Second, for our purpose, we should only visit two types of pages, text based pages such as HTML files or plain text files, and PDF files that we can convert to text. We can simply use file extension to check to see if a web page falls into these categories. In Bucknell domain, an HTML page would have the extension of *.html or *.xml, while a text file typically has the extension of *.txt. A PDF file should have the extension of .pdf. You can use the Linux command pdftotext to convert a PDF file into a text file.
We should limit our crawler to visit web pages from the CS course websites only. In the appendix of this assignment, a list of course websites is provided. You don't have to visit every single one on the list. But your program should at least be able to visit a few different course websites and your results should contain no fewer than a few hundred pages.
At this point, your program is able to visit a number of web pages, parse out all URLs leading to other web pages to be visited, and parse out all words in a text file (or PDF file). You are now to build a simple indexing system that will match the search query with the web pages that contain the query words.
The basic idea in this simple indexing system is to build a inverted index list such that each search query word can lead to the list of web pages that contain the query word. There are many ways of building an inverted indexing system. You can check out this original paper describing the original Google indexing system. We will follow a very simple approach. You are asked to build a list of words to be indexed, each of these word leads to a list of web pages that contain the word. The following is an illustration of this structure.
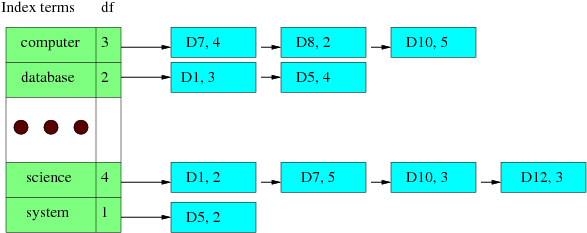
Figure: An Example of Inverted Indexing System
In the example, we have a sorted list of words (computer, database, ... , science, system). Each index node in the index term list has three fields, the index term (word), the document frequency, or DF (the number of documents containing the word in the collection), and a pointer to a list of document nodes, each of which contains a document ID and the term frequency (the number of times the word appears in that document). For example, the term science has a DF value of 4, meaning four documents contain this word, followed by the four document nodes. In this case, D1 contains the term two times, D7 five times, so on and so forth. In this manner, a given word can lead to a list of documents, thus we call it inverted indexing system.
When a search query is received, the search engine goes through the index term list, finds the word, retrieves the list of documents (web pages) and send these web page URLs to the client (the browser) for display.
Stopwords Removal
After the text is tokenized (broken into words), we should remove the stopwords that we don't want to include in the index collection. Here you may come up a list of stopwords of your own, or you may search the internet to find a source that has a list of common stopwords. These lists may differ. That is fine. Your program need to go through the list of words extracted from the text and then remove the ones that are in the stopwords list.
In general, a real search engine would take other steps to "clean up" the word list such as stemming. We will keep it simple so no other processing is required. The outcome of this strategy is that some time we may find that two words that mean the same (or very similar) would end up as two separate words. For example, the word computer and computers may be considered as two words in our system. This is not ideal, but acceptable. You might consider taking a text processing step called stemming to take care of this situation. But it will add complexity to the program. You are not required to stem words in this project. You might ask if we can simply convert the plural form of a word to singular form by removing the trailing "s" or "es". The answer is not that simple. Consider the words "class" or "yes". The stemming process turns out to be pretty complicated. That is why we are not asking you to implement it in this project.
While collecting web pages over the network, we should consider two issues. One is that we try not to overcrowd the network; the second is that we should try not to repeat the work that has been done. We will discuss these two issues in this section.
Network capacity is a very precious resource. We should use it very carefully. We can choose our program options to make our program less aggressive in terms of using network capacity. At the same time, doing so can also save our own time in running the program less frequently. We can do at least the following two things to help this issue.
www.eg.bucknell.edu with breaks in between some number of pages. For example, for each 40 pages you visit, stop your crawler a few seconds using the Linux sleep() function.You are to submit to your Gitlab account the following by the deadline.
The following is a list of course websites that your program may visit.